进程和服务
进程类型
Druid有以下几种进程类型:
服务类型
Druid进程可以按照您喜欢的任何方式部署,但是为了便于部署,我们建议将它们组织成三种服务器类型:
- Master
- Query
- Data
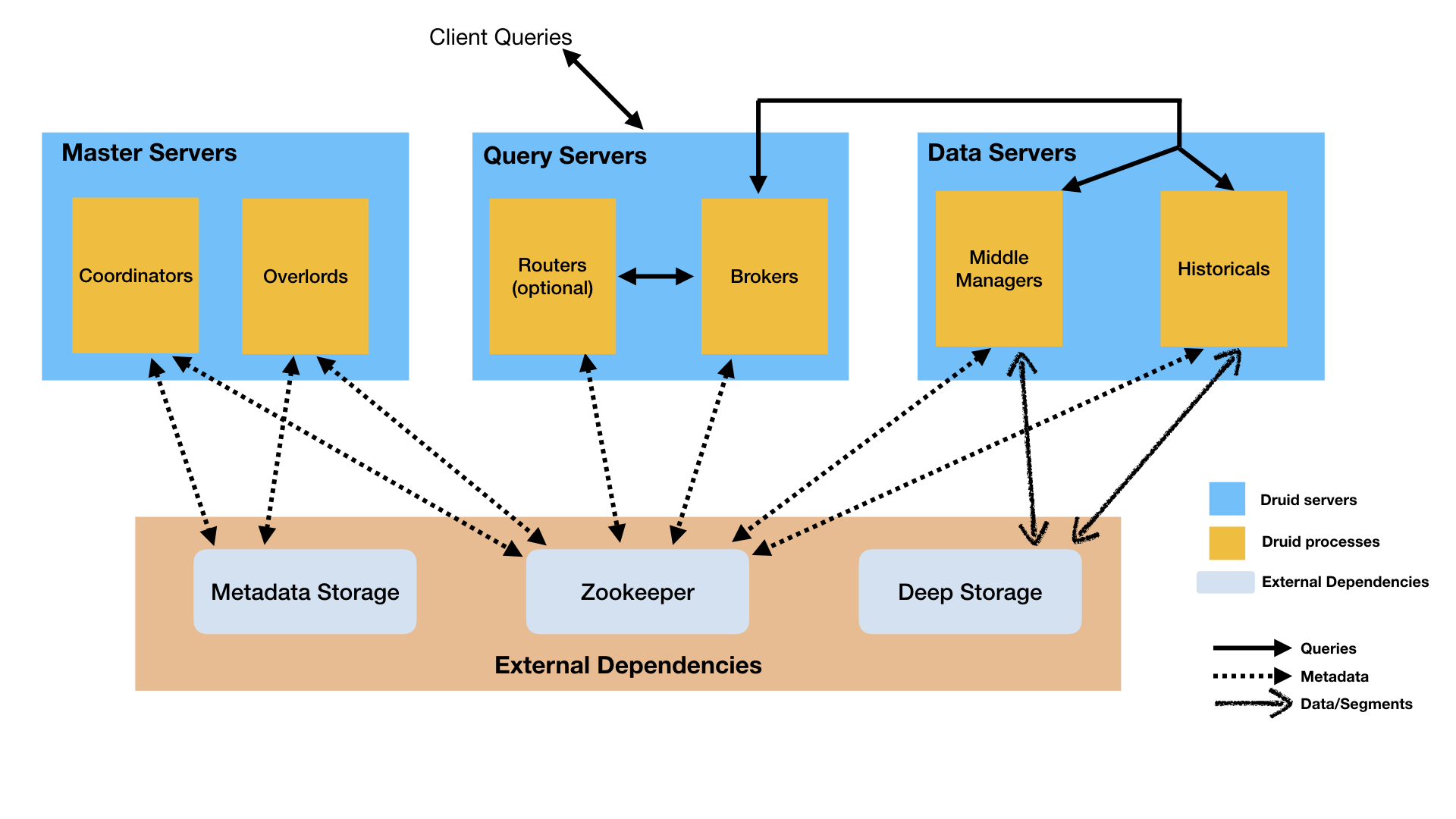
本节描述Druid进程和建议的Master/Query/Data server组织,如上面的架构图所示。
Master服务
Master服务管理数据的摄取和可用性:它负责启动新的摄取作业并协调下面描述的"Data服务"上数据的可用性。
在Master服务中,功能分为两个进程:Coordinator和Overlord。
Coordinator进程
Coordinator 监视Data服务中的Historical进程,它们负责将数据段分配给特定的服务器,并确保数据段在各个Historical之间保持良好的平衡。
Overlord进程
Overlord 监视Data服务中的MiddleManager进程,并且是Druid数据接收的控制器。它们负责将接收任务分配给MiddleManager,并协调数据段的发布。
Query服务
Query服务提供用户和客户端应用程序交互,将查询路由到Data服务或其他Query服务(以及可选的代理Master服务请求)。
在Query服务中,功能上分为两个进程:Broker和Router。
Broker进程
Broker从外部客户端接收查询并将这些查询转发到Data服务器, 当Broker接收到子查询的结果时,它们会合并这些结果并将其返回给调用者。用户通常查询Broker,而不是直接查询Data服务中的Historical或MiddleManager进程。
Router进程(可选)
Router进程是可选的进程,相当于是为Druid Broker、Overlord和Coordinator提供一个统一的API网关。Router是可选的,因为也可以直接与Druid的Broker、Overlord和Coordinator。
Router还运行着Druid控制台,一个用于数据源、段、任务、数据进程(Historical和MiddleManager)和Coordinator动态配置的管理UI。用户还可以在控制台中运行SQL和本地Druid查询。
Data服务
Data服务执行摄取作业并存储可查询数据。
在Data服务中,根据功能被分为两个进程:Historical和MiddleManager。
Historical进程
Historical 进程是处理存储和查询"Historical"数据(包括系统中已提交足够长时间的任何流数据)的工作程序。Historical进程从深层存储下载段并响应有关这些段的查询,他们不接受写操作。
MiddleManager进程
MiddleManager 进程处理将新数据摄取到集群中的操作, 他们负责读取外部数据源并发布新的Druid段。
Peon进程
Peon 进程是由MiddleManagers生成的任务执行引擎。每个Peon运行一个单独的JVM,负责执行一个任务。Peon总是和孕育它们的MiddleManager在同一个主机上运行。
Indexer进程(可选)
Indexer 进程是MiddleManager和Peon的替代方法。Indexer在单个JVM进程中作为单个线程运行任务,而不是为每个任务派生单独的JVM进程。
与MiddleManager + Peon系统相比,Indexer的设计更易于配置和部署,并且能够更好地实现跨任务的资源共享。Indexer是一种较新的功能,由于其内存管理系统仍在开发中,因此目前被指定为实验性的特性。它将在Druid的未来版本中继续成熟。
通常,您可以部署MiddleManagers或indexer,但不能同时部署两者。
服务混合部署的利弊
Druid进程可以基于上面描述的Master/Data/Query服务组织进行混合部署,这种部署方式通常会使大多数集群更好地利用硬件资源。
但是,对于非常大规模的集群,可以分割Druid进程,使它们在单独的服务器上运行,以避免资源争用。
本节介绍与进程混合部署相关的指南和配置参数。
Coordinator和Overlord
Coordinator进程的工作负载往往随着集群中段的数量而增加。Overlord的工作量也会根据集群中的分段数而增加,但程度要比Coordinator小。
在具有非常大量的段的集群中,可以将Coordinator进程和Overlord进程分开,以便为Coordinator进程的分段平衡工作负载提供更多资源。
统一进程
通过设置 druid.Coordinator.asOverlord.enabled 属性,Coordinator进程和Overlord进程可以作为单个组合进程运行。
有关详细信息,请参阅Coordinator配置。
Historical和MiddleManager
对于更高级别的数据摄取或查询负载,将Historical进程和MiddleManager进程部署在不同的主机上以避免CPU和内存争用。
Historical还受益于为内存映射段提供可用内存,这也是分别部署Historical和MiddleManager进程的另一个原因。